

Logs are fundamental to operating software. They're what everyone has locally, and one of the first signals checked when problems occur. Logs are used for everything from access logs to application logs, security logs, infrastructure events, and more.
Logs are undoubtedly powerful, but they are also plagued by a common challenge: their format. Observability and Log Management solutions prefer nicely structured data to filter, aggregate, group, and visualize, but often this is not available. And when it is, it is toilsome and requires continuous investment and vigilance.
In this post, we will examine the shapes and formats logs come in, the solutions the industry has developed, and our Log AI-based approach to unstructured data.
The Problem
You have been there: You access/download a log file to identify and fix a problem. Now you have megabytes of text on your machine, and you somehow try to determine what is happening. You use a text editor to inspect a file (it likely crashes), then you use less or the MacOS Console.app (which handles large files surprisingly well). And now you are in a world of pain: Text, so much text! Searching within the file only gets you so far. This is bad – and in any reasonably large system, you will suffer a lot trying to identify anything.
With an observability solution, you will have a much better time. The solution won’t crash; you don’t have to hunt down the file and get valuable context. But oh darn, the logs aren’t parsed! As far as the observability solution is concerned, these are still just lines of text. So, there is no ability to (easily) filter for a log level, customer, or anything.

But why is this still the case in 2024? The core challenges have been the same for a long time:
- Logs are typically written to storage, and then read for persistence in observability solutions in…
- A variety of text formats ranging from very structured to plain text and from (quasi) standardized to proprietary.
- There are a huge number of log formats. Some services emit logs in more than one format.
Here is an example of an Istio log line like it would appear on a docker logs output. There is nothing special or wrong about it. It lists the typical date time, log level and a few more things. In fact, it is partially structured, showing size:31.7kB.
12024-12-08T19:51:43.423042Z info delta EDS: PUSH request for node:istio-ingress-6ddf6f4749-rd6m5.istio-ingress resources:118 removed:0 size:31.7kB empty:0 cached:118/118 filtered:0
So, how do observability solutions turn such a string into nicely structured information so you can filter for INFO logs reporting a size larger than 30kB? Well, this exercise is most commonly left to the user in one of two ways:
- Parse the logs as they are being read from storage before they are being sent to the observability solution. For example, via the OpenTelemetry
filelogreceiver and its operators. - Parse the logs at query time within the observability solution through the definition of a query (often in a Kusto-like query language).
Both options typically require the definition of a regular expression to do the parsing work. And more often than not, the log line you are looking for is the one that is not parsed –or– that is wrongly parsed! This costs valuable time, causes headaches, and, in the worst case, sends you down the wrong rabbit hole.
Neither of these solutions is perfect. They create toil, are error-prone, and are quite hostile to beginners. Let’s look at an alternative approach.
Note, with OTel your processes can also directly send the nicely structured logs out!
The Vision
In an ideal world, logging data is –out of the box– as rich in semantics and structure as possible, such as structured tracing data. That way, you can get automatic aggregations, suggestions for business-relevant keys and structures in the logs, and more. And ideally, you don’t have to care about any of the abovementioned details. Imagine a set of platform engineers taking care of this for you!
Does it sound too good to be true? It is challenging! But we are working hard to make it a reality. In fact, we recently released Dash0's Log AI as a beta feature. This is a magical experience matching how we think about AI at Dash0. AI enriches the data, unlocks capabilities, and makes things easier for our users. But, it is not a place you go to within the product.

Log AI starts by identifying log severities. These are crucial to understanding how your system is performing. You unlock visual color coding in log lists and the log overview chart, but also alerting on errors! It is hard to overstate how important this simple semantic is. The difference between knowing whether your system is facing errors vs. not facing errors is huge!
In the next step, we will tackle custom-structured segments from logs, such as the size field in the above Istio example. Then, you can fully leverage your existing unstructured logs without manual toil.
You may be wondering about the remaining unknown logs in the screenshot above. Sometimes, we cannot infer a severity. That's just a reality we are striving to improve. Those unknown logs are most commonly access logs, e.g., of NGINX. We still have to decide what log level they should be and whether users need control of this translation 🙂.
How it Works
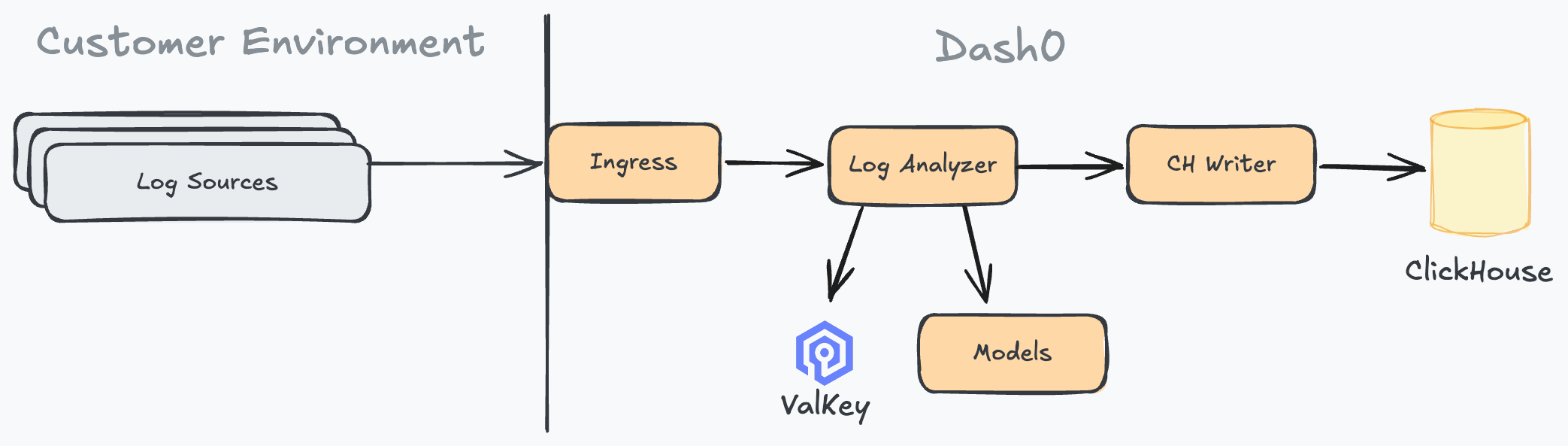
Dash0's Log AI is executed as part of the log ingestion pipeline so that we can store processed logs. This is challenging because the approach needs to work for billions of logs every day while being economical. Consequently, we must do more than just invoking an LLM to get the job done (although they are surprisingly good at it!). With this in mind, we had to model the solution so that the costs do not scale with the volume of data.
To achieve this, we leverage a combination of models and semantics-aware heuristics to understand log structures. OpenTelemetry's semantic conventions provide extra context that helps us understand the data – especially when paired with our cross-signal resource correlation and entity identification. The outcome is a set of patterns we use to extract the fields relevant to end-users – like the log severity! The pattern extraction ends with various automated checks, ranging from "Does it parse the input?" to validation of extracted segments against allow lists and more.
At scale, most AI models are challenging to execute for every log record. We have been there in the past: A great AI model but no means of running it economically. It sucks! Not this time! 🥹
We are reusing as many patterns as possible by fingerprinting the source and likely format and reusing those patterns for similar log records (nasty detail: Processes can log in multiple formats). To that end, we are leveraging ValKey as a caching solution to map fingerprints to patterns. We also monitor how often these patterns match, so they can be updated as soon as the underlying log format significantly changes.
One of our North Star metrics for this capability is "severity patch coverage." What percentage of eligible logs can we successfully patch? Of course, it is monitored within Dash0.

Although Log AI doesn’t require a specific model to be trained, we do adopt traditional machine learning practices to make sure that we keep improving it: The implementation described above is also reproduced in an offline evaluation pipeline, where the input logs come from a mixture of common domain datasets and our own internal data. The metrics that come out of this evaluation confirm that the process follows the principle of graceful degradation: We almost always succeed to understand the log structure, and when we do, the extracted data is always correct – when we don’t, no side effects are produced.
Next Steps and Conclusion
Our beta customers like it a lot – after all, they get better data without lifting a finger. Log AI is modeled after our AI philosophy: Making AI work for you behind the scenes!
Now, we are working on its next evolution, named attribute extraction and message cleanup. We are very excited about the possibility of not having to manually parse log files.

