
The original motto of Dash0 is data in color. Specifically, it should be red if it’s bad, yellow if it is not great, and some shade of gray if it’s OK. That is: colors in Dash0, as well as their absence, are used very deliberately to attract your attention where it is most needed.
There are only two possible reasons why Dash0 would color a UI element in red or yellow:
- Checks set by you: When you define check rules in Dash0, you either specify thresholds via the query builder or define a PromQL query. Failed checks affect the health of the resources they are associated with, and those resources will be colored yellow or red, depending on the severity of the failure.
- OpenTelemetry semantic conventions specify for a number of attributes which values represent errors or warnings. Those are also colored red or yellow, respectively. (Moreover, there are also some cases, like HTTP status codes 3xx, which in Dash0 we color with an informational blue because they are not really problematic but noteworthy.)
Our goal is to enhance your observability experience without unnecessary distractions, so when you see color, it’s for a reason — to make you faster at troubleshooting!
Check rules and Checks
Check rules is how you tell Dash0 what you consider unhealthy statuses of the applications and systems you monitor.
However, coming up with these rules is sometimes tricky, especially if you are not entirely familiar with the technology, or you are struggling with the empty canvas. It can be daunting to specify new check rules, knowing that, if you get them wrong, somebody gets woken up at 3 AM at night. For this reason, Dash0 will put at your fingertips the community-curated check rules as “Awesome prometheus alerts”: with one click, you can import as checks in Dash0 hundreds of alert templates defined for various technologies and their failure modes, like “High number of prepared Statements” of your MySQL Database or “CPU is underutilized” for a EC2 instance in your AWS cloud, as you can see in the following example:

Let's make sure that my hosts are well utilized so that I can effectively use my AWS bill. Then, let's take a closer look at how that impacts the coloring of resources in my Dash0 experience. From the template, I can immediately see that the necessary metrics are available, so I am going to use the template.

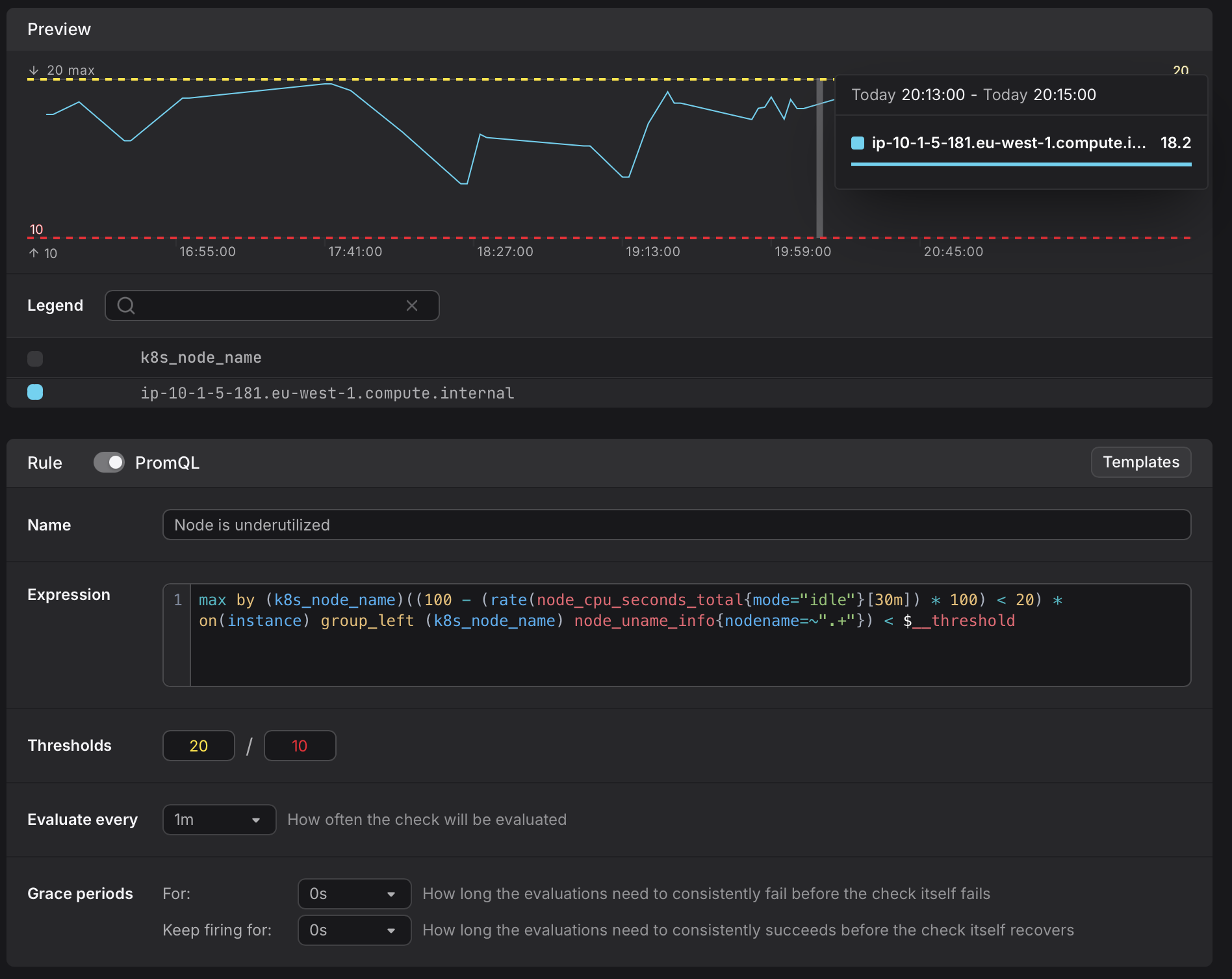
The check rule editor gives me a preview of the time series and allows me to specify up to two thresholds to be alerted: one for critical situations in Dash0, and one for less serious, degraded situations.
The structure of the time series defines two key aspects:
- The rows indicate the alerting granularity, where each distinct time series represents a potential point of failure that can trigger an alert.
- The columns determine the resource being highlighted in the resource table and map, with each attribute related to a resource mapping the failed checks to the corresponding resource.
Scrolling through the attributes I realize that my time series are split by cpu: the virtual host has four CPU cores, and utilization is reported separately for each. This is too fine a granularity, and will certainly lead to many alerts and for my check rule for underutilized nodes.

I can adjust the PromQL expression to aggregate the time series by selecting the maximum value of my cpu’s per k8s_node_name. Now I get one time series per k8s node, which is the granularity I was looking for. The attributes that I split by my query will affect if the failed check will be attributed to the respective resource and thus the current configuration makes sure that only the node resource will appear in the respective colors.
Semantic Conventions
Let's take a look at the http.status_code attribute from the HTTP semantic convention. Status code 500 denotes an error occurring server-side, so attributes with http.status_code=500 appear in red within the span table.
Besides, when troubleshooting, you should be distracted as little as possible by having to google things on the side, so Dash0 has various knowledge bases built-in, like what each HTTP or gRPC status code means:

Why red really matters
Red is a universal symbol of urgency, signaling something that demands immediate attention. But for red to truly serve its purpose, it must indicate a genuinely important problem — not yet another error you want to ignore, or something you don’t understand. So, when a resource turns red, it’s because you configured it that way by specifying a check rule. The same applies to yellow: resources are marked as degraded because you specified those thresholds.
With Dash0, you have complete control. You can always fine-tune the conditions to align with your specific needs, ensuring that red means what it should: an actionable issue that requires your intervention.
Because the question “Why is this red?” isn’t about aesthetics but precision. When something in Dash0 turns red, it’s because you set the criteria, making it a meaningful, tailored signal worth investigating. And since we design Dash0 with a color palette that makes red (and yellow) stand out, your eye won’t miss it!

