Within OpenTelemetry, resources serve to describe which entity is generating telemetry data, such as a process, container, or Kubernetes pod. At the data level, resources are defined by attributes (key/value pairs). OpenTelemetry defines a large (and expanding) set of semantic conventions for resource attributes, enabling adopters to describe the system being monitored in a way that other information systems understand.

In this example, you can see different attributes that describe the host the resource represents, the cloud it uses, and the Kubernetes environment it was running on.
Through the context provided by resources, if telemetry data indicates latency in a system, the resource attributes can help narrow down the issue to a specific container, pod, or deployment.
How OpenTelemetry Resources are defined in OTel SDKs
Let us look at the OpenTelemetry Node.js SDK to learn how to configure resources with attributes specified in semantic conventions, available in Node.js via the @opentelemetry/semantic-conventions NPM package:
1234567810111213141516182022import { Resource } from '@opentelemetry/resources';import {SEMRESATTRS_SERVICE_NAME,SEMRESATTRS_SERVICE_NAMESPACE,SEMRESATTRS_SERVICE_VERSION,SEMRESATTRS_SERVICE_INSTANCE_ID} from '@opentelemetry/semantic-conventions';import { NodeSDK } from '@opentelemetry/sdk-node';const sdk = new NodeSDK({resource: new Resource({[SEMRESATTRS_SERVICE_NAME]: "shippingcart",[SEMRESATTRS_SERVICE_NAMESPACE]: "logistics",[SEMRESATTRS_SERVICE_VERSION]: "1.2.3",[SEMRESATTRS_SERVICE_INSTANCE_ID]: "275ecb36-5aa8-4c2a-9c47-d8bb681b9aff"}),// other configuration});sdk.start();
In this example, a resource is defined with the resource attributes service name, namespace, version, and instance ID. These four service attributes model which logical component of the monitored system emits the telemetry. The attributes will be associated with every piece of telemetry emitted by this OpenTelemetry-instrumented application, and so they help answer fundamental troubleshooting questions like:
- Which service created this error log?
- What is the performance difference between our service's latest version and the previous version?
- How is the load distributed among the various instances of our service?
Aggregations and logical grouping
Through OpenTelemetry resource attributes, tools that rely on them can perform logical aggregations of resources, like correlating telemetry from all the pods contributing to the same service. An example of this is a service with three pods, each with the service.name resource attribute set to the same value shoppingcart. This enables the aggregation of logs and spans across all three pods into a single "shopping cart" service. This logical context is crucial for understanding metrics such as the number of calls received or errors generated by the service. The association of each Span, Log, and Metric in OpenTelemetry to precisely one resource facilitates this aggregation.

Similar aggregations can be performed for all other resource attributes, like understanding the performance of a Kubernetes cluster or the traffic difference between two AWS zones—all possible thanks to the resource concept of OTel. Aggregations can also be performed at multiple levels at the same time: if we have a service and we want to see the difference between the service running in a US cloud region and a European cloud region, we can aggregate on a service level and then split it up (group by) cloud.region or even cloud.availability_zone, defined by the Cloud semantic conventions.
Resource Information for Filtering and Context
The metadata specified via resources can also help narrow down signals in the large amount of noise we have nowadays in the observability of large systems.
One option to reduce the noise is to filter signals. Filtering can be done based on the underlying resources. For example, if I know that a problem occurred in a specific cloud region or availability zone, I can filter out all the signals of the other regions/zones. The experience of filtering for or against particular attributes and their values can make or break the user experience for triaging. End users should be able to apply filters by interacting directly with the data, e.g., when displayed in tabular form.

However, the tool should also provide a way to estimate the impact of filters before they are applied, facilitating the triaging by following “breadcrumbs” of where most errors cluster.

Ideally, the observability tool will also automatically suggest filters. For instance, if the system detects that Spans are consistently slow when executed on a particular host, it can recommend a filter for that host. This filter would include all the relevant information, such as the corresponding Metrics and Logs, to facilitate root cause analysis.
OpenTelemetry Resources to explore and understand your architecture
Through the OpenTelemetry semantic conventions, resources also have an implicit structure and hierarchy that can be used to quickly understand and explore complex architectures - from both application and infrastructure perspectives.

OpenTelemetry Resources and Metrics for Infrastructure monitoring
In the same way resources can be used to model logical components of our systems, i.e., the services, they can also be used to model the infrastructure underpinning them. Using these infrastructure-related metadata, one can have an overview of, for example, CPU and memory utilization of hosts or the capacity of pods.
Solutions such as Dash0 can optimize for this for the first time ever because OpenTelemetry's semantic conventions standardize attributes and metrics!
Adding Resource Information to OpenTelemetry signals
OpenTelemetry offers several approaches to specify resources:
- Define resource attributes in your code using OpenTelemetry SDKs
- Leverage resource detectors to automatically detect resource information from the environment. Standard detectors include those for the operating system, host, process, container, Kubernetes, and cloud-provider-specific attributes.
- Through centralized configuration within OpenTelemetry collectors
- Using environment variables
That's the power of OpenTelemetry: Choose as much or as little as you need. Skip attributes you don't care about, and add those crucial to your organization – no matter whether they are standardized or proprietary!
Resource Detectors
Resource detectors can automatically add resource attributes to signals. They help you start quickly with high-quality information without manual toil and fewer bugs.
Resource detects come in two flavors:
- Resource detectors running within the observed processes through the language-specific SDKs, e.g., directly within your Go, Node.js, or JVM process, and
- resource detectors running within the OpenTelemetry collector.
Let's look at a code sample for the former: An in-process resource detector for AWS EC2-instance attributes within a Node.js process. AWS EC2-instance attributes are essential to answer fundamental questions such as:
- What VM is the process running on?
- Are instances of our services running within multiple availability zones?
- What's the Cloud account again this process is running in?
All these can be provided by the @opentelemetry/resource-detector-aws NPM package!
13456import { awsEc2Detector } from "@opentelemetry/resource-detector-aws";new NodeSDK({// other configurationresourceDetectors: [awsEc2Detector],});
The code example above shows how easy it is to set up these detectors. Registering it with the Node.js SDK is enough in most situations.
As mentioned, you can also detect resource attributes within the OpenTelemetry collector. Using the OpenTelemetry collector for detection has some benefits, such as centralizing resource detection configuration. Let's see how you could leverage the resource detection processor to detect a variety of Azure resource attributes.
12345processors:resourcedetection/azure:detectors: [env, azure]timeout: 2soverride: false
The processor can detect many more attributes, such as host, container, Heroku, and Kubernetes attributes; check out its readme to learn more.
Specifying resource information via an environment variable
Environment variables offer a great way to configure OpenTelemetry SDKs and resource attributes. Because they are environment variables, you can externally manage them, set them, and ensure consistency, e.g., within your Kubernetes workload manifests.
At their core, all OpenTelemetry SDKs must extract information from the OTEL_RESOURCE_ATTRIBUTES environment variable and merge it with whatever you provided through an in-code SDK configuration. One of the best things about this environment variable is that it works no matter whether you manually initialize an OpenTelemetry SDK, use the OpenTelemetry operator, or use any other proprietary auto-instrumentation mechanism!
OpenTelemetry supports many environment variables for all kinds of configurations. Let's just see how to define the attributes we previously defined through in-code SDK configuration.
12OTEL_SERVICE_NAME="shippingcart"OTEL_RESOURCE_ATTRIBUTES="service.namespace=logistics,service.version=1.2.3,service.instance.id=275ecb36-5aa8-4c2a-9c47-d8bb681b9aff"
Understanding OpenTelemetry Resources
Resources in OpenTelemetry are, at the most fundamental level, “just” a set of semantic attributes. This means there is no fixed, structured representation of a resource. This can be confusing at first, but it is a compelling concept: resource can be a service, a pod, a host or an AWS region - depending on which resource attribute you want to use to aggregate telemetry.
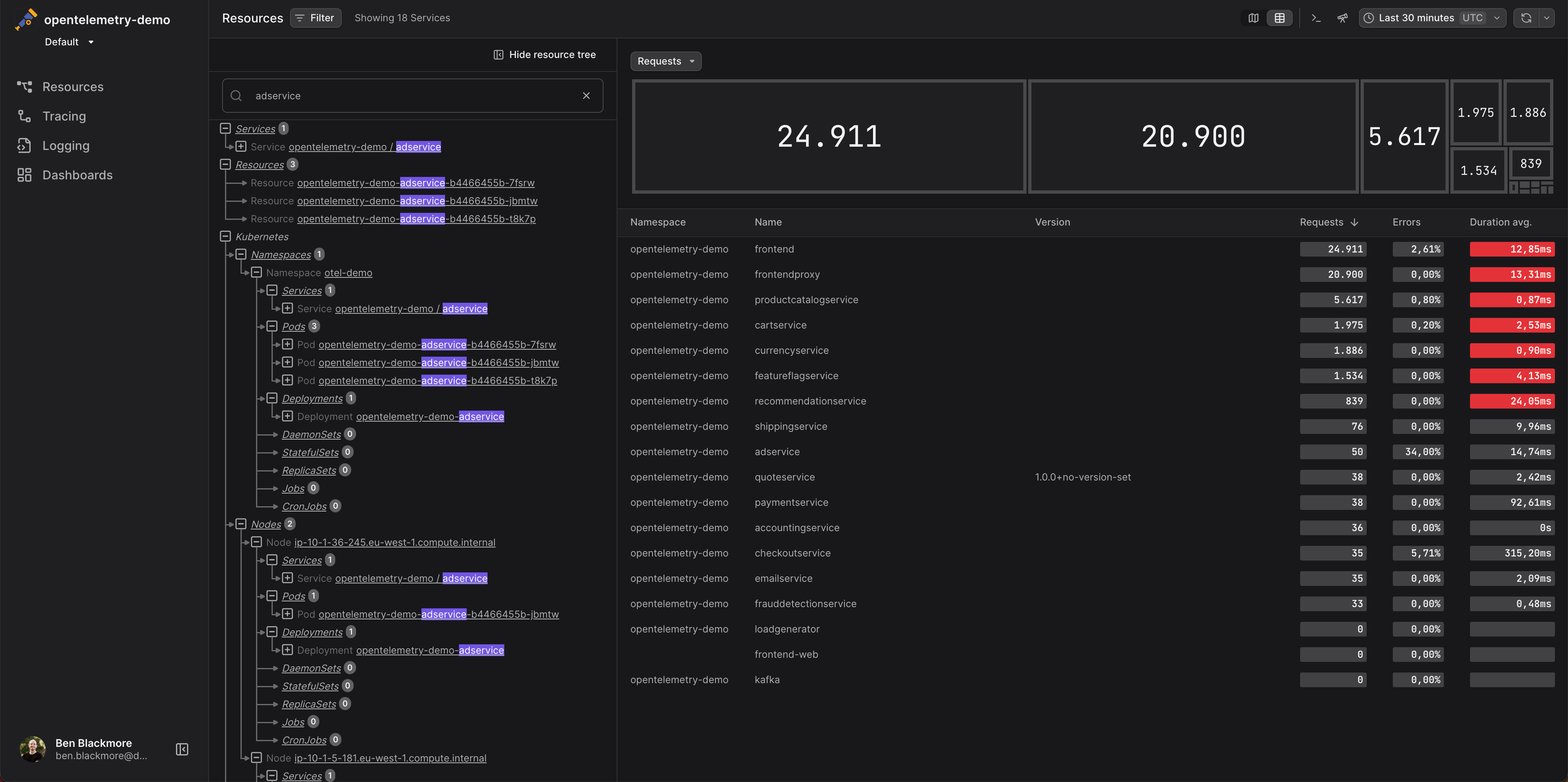
At Dash0 we have opted into a concept where you can have the full flexibility, but also provide some built-in representation of resources - e.g. Service or Pod.

If you select the Service representation in the above shown resource map screenshot, Dash0 will aggregate all the data based on the service.* resource attributes and show services in the resource map—this will give you a logical or application-centric view of your system. If you select “Resource”, you will get a more infrastructure-related view, e.g. seeing every instance/Pod of a service separately on the map.
Is a service a resource?
Since resources are just collections of attributes, and the service.* namespace plays such a central role in OpenTelemetry, so one could wonder whether a logical component like a service can be represented as a “resource” the same way a Kubernetes pod can.
This is an interesting discussion, and as you have read above, we think the answer is yes. But you could also argue that the service is just an aggregation of resources on the service.name attribute rather than a resource in and of itself. So, for example, three pods running the same process of a service can each have the same service.name attribute and, if you aggregate them by it, you will see the number of calls to the service which includes all the calls to the three pods. Essentially, the resources are the three single instances of the service. The same is true for resources like Kubernetes namespaces.
In Dash0 we do not distinguish those concepts. You can select the representation or aggregation of resources as natural as they are in the logical and physical world of your application and infrastructure.