Automatically adjusts the size of a Kubernetes cluster based on resource demands.
The Cluster Autoscaler works by continuously monitoring the cluster for two main conditions:
When it detects unschedulable pods, it scales up the cluster by adding nodes to accommodate the workload. Conversely, when it identifies underutilized nodes, it scales down the cluster by removing them after migrating their pods to other nodes. This process helps optimize resource usage, improve performance, and reduce costs by ensuring the cluster maintains just enough capacity to handle current workloads without manual intervention
When deploying the Cluster Autoscaler, you can enable Prometheus metrics by adding the following annotations to the Cluster Autoscaler Helm chart.
For more details see cluster-autoscaler Helm chart.
If you are using Prometheus to scrape metrics from your Kubernetes cluster, you can configure Prometheus to scrape the cluster autoscaler metrics by adding the following configuration to your Prometheus configuration file.
You need to verify that the pod labels in the scrape configuration match the name of the cluster-autoscaler pod.
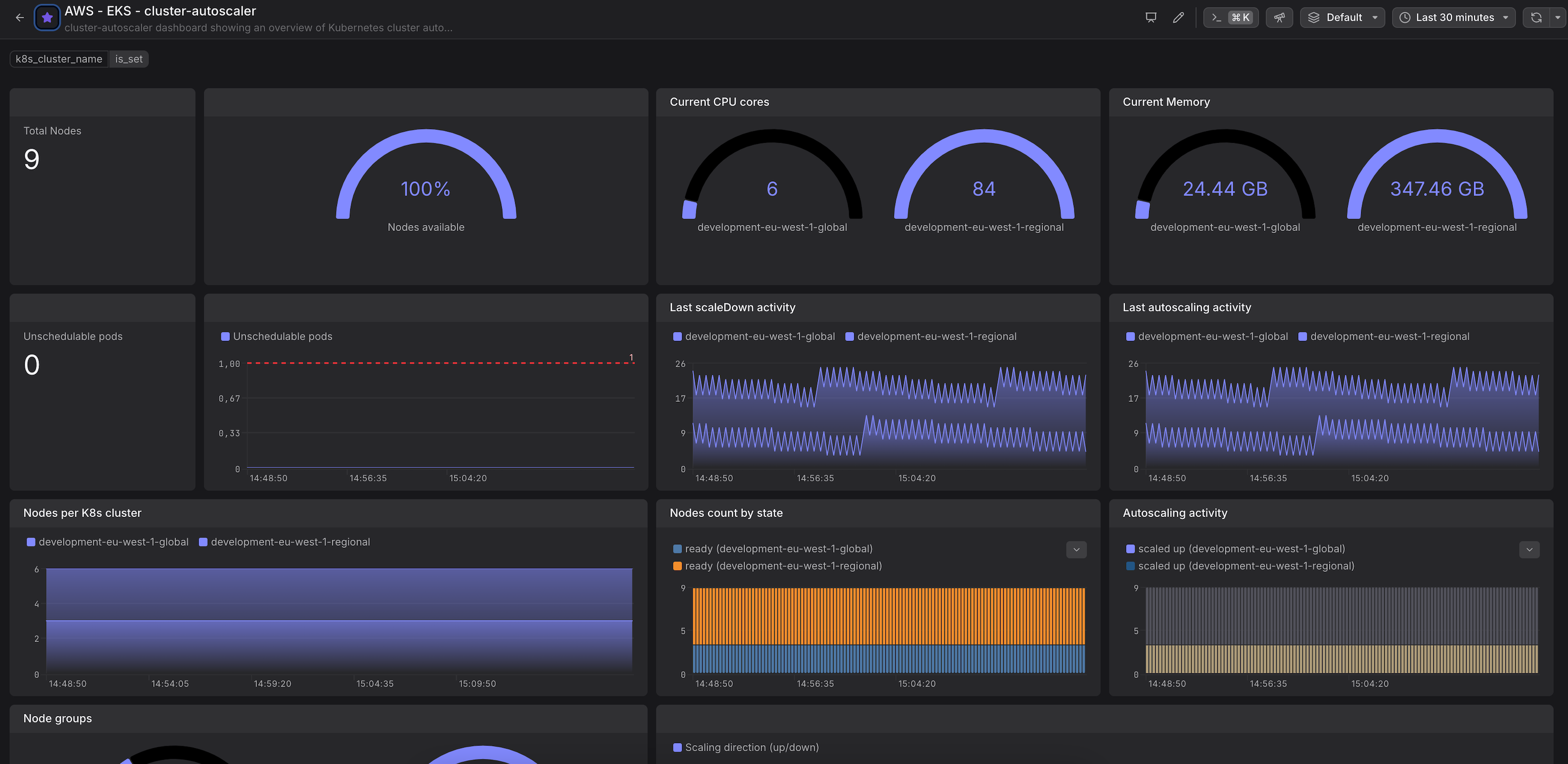
Dashboard with cluster-autoscaler metrics